Så här skapar du ett pivottabell i Excel 2016

Skapa ett pivottabell i Excel 2016
Vad är ett pivottabell?
Ett pivottabell är ett fint namn för att sortera information. Den är idealisk för att beräkna och sammanfatta information som du kan använda för att bryta ner stora tabeller till precis rätt mängd information du behöver. Du kan använda Excel för att skapa ett rekommenderat pivottabell eller skapa en manuellt. Vi tittar på båda.
Rekommenderat pivottabell
Introducerad i Excel 2013 är ett rekommenderat pivottabell en förutbestämd sammanfattning av dina data som Excel rekommenderar för dig. Du kanske inte får den information du behöver beroende på din dataset, men för snabb analys kan det vara användbart. För att skapa en markerar du datakällan (cellintervallet i arbetsboken som innehåller data som du vill analysera.) Välj sedan fliken Infoga och sedan Rekommenderade pivottabeller.

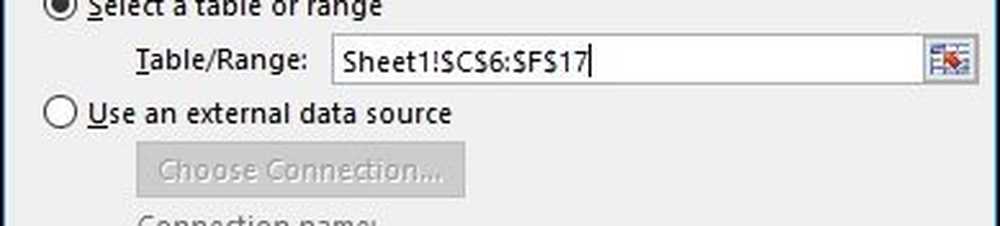
När dialogrutan Välj datakälla visas klickar du på OK.
Ett galleri med rekommenderade PivotTable-stilar visas som ger förslag på hur du kanske vill analysera de valda data. I följande exempel går jag med grev av anställningsnamn efter timmar arbetade i januari. Din vilja variera beroende på vilken typ av data du sorterar. Klicka på OK.
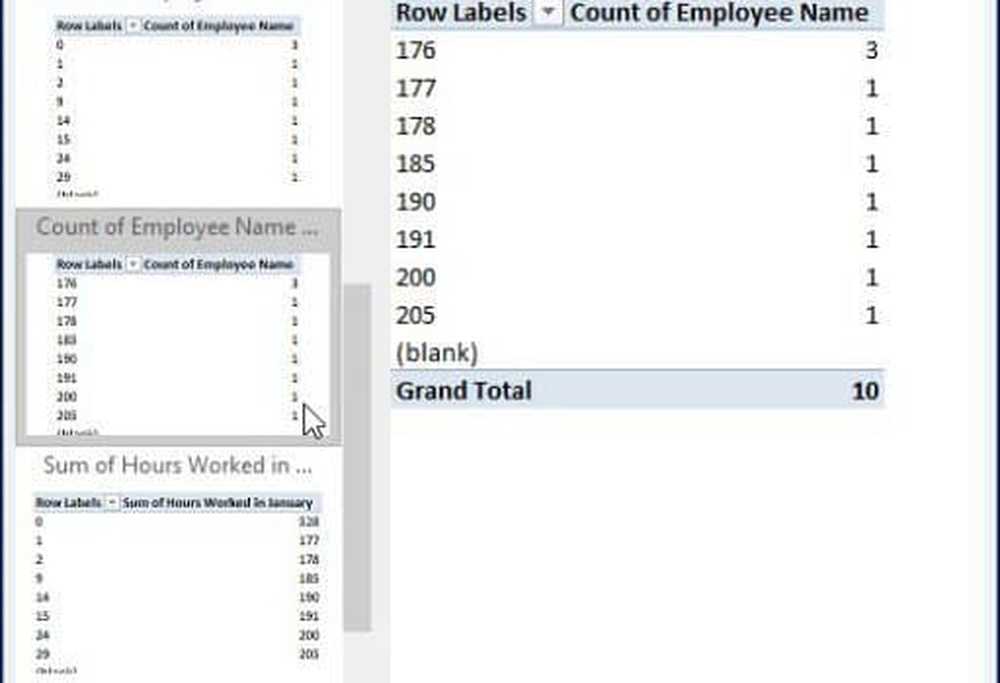
Som du kan se i tabellen nedan kan jag få en uppfattning om hur många personer som arbetade en viss timme i januari. Ett scenario som detta skulle vara bra att se vem som kan arbeta det svåraste, arbeta övertid och från vilken avdelning inom ett företag.
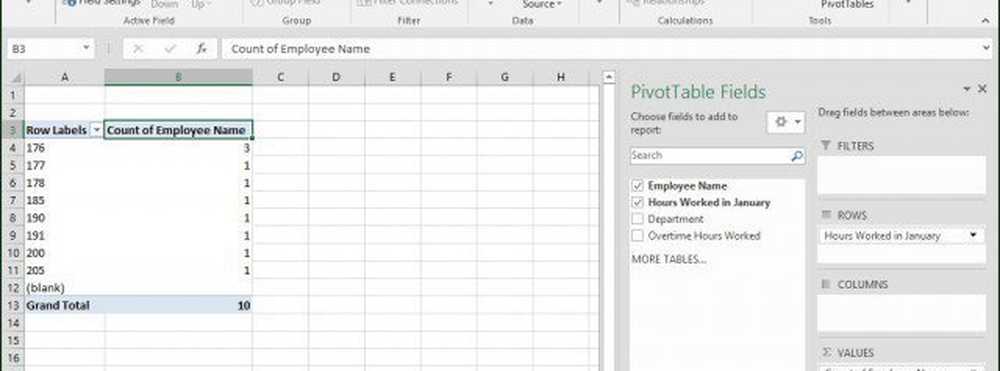
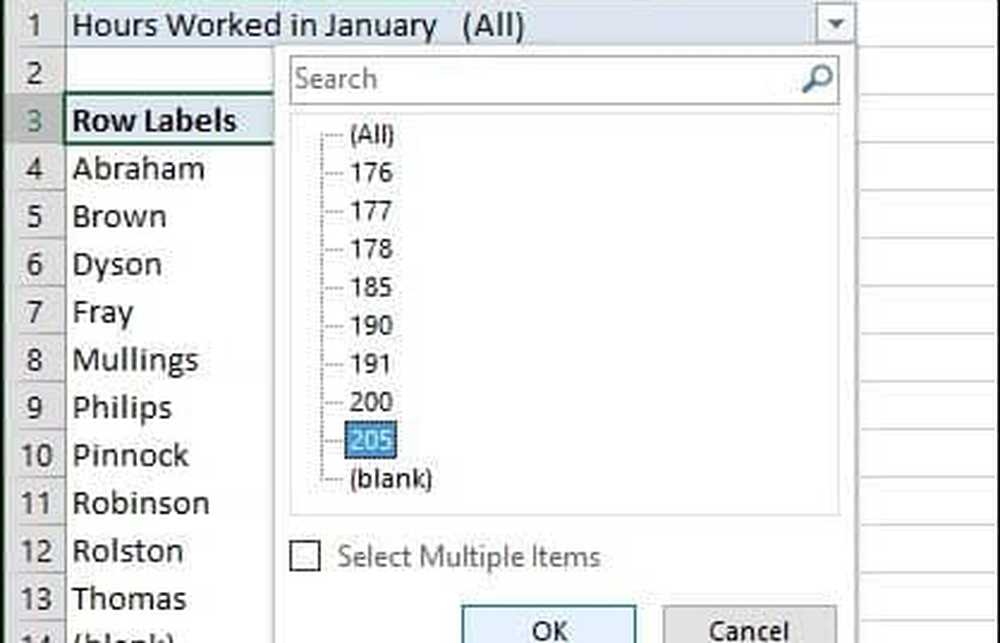
För att göra det mer intressant, låt oss gräva vidare och ta reda på vilken medarbetare som arbetar mest. Som du kan se visas uppgiftsrutan för pivottabellen till höger och visar ytterligare verktyg som jag kan använda för att sortera och filtrera. För följande exempel ska jag lägga till Timmar arbetade i januari till området Filters och lägg till medarbetarens namn till radområdet. Efter det har du märkt att ett nytt fält har lagts till i det ark som heter Timmar arbetade i januari.

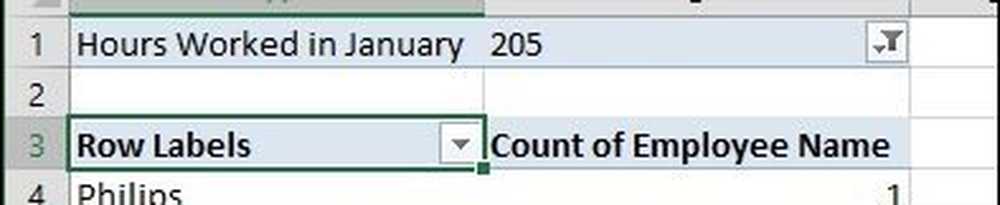
När jag klickar i filterrutan kan jag se det lägsta och det högsta. Låt oss välja högst som är 205, klicka på OK. Så en anställd med namnet Philip arbetade de flesta timmar i januari. Det blir inte lättare än det.
Skapa en pivottabell från grunden
Om du vill ha mer kontroll över hur ditt pivottabell är utformad kan du göra det själv med hjälp av det vanliga pivottabellverktyget. Välj igen datakällan eller det område där data lagras i arbetsboken och välj Infoga> PivotTable.
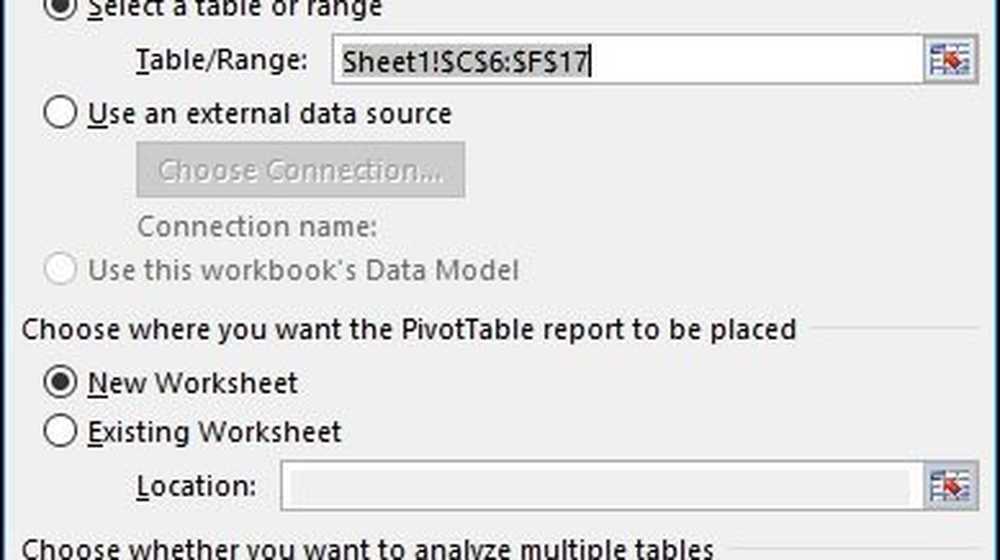
en Skapa pivottabell dialogrutan visas med flera alternativ. Eftersom jag arbetar med datakällan från själva kalkylbladet lämnar jag standard. Du kan välja att lägga till pivottabellen till ett existerande kalkylblad eller en ny. I det här fallet lägger jag in det i ett nytt ark.
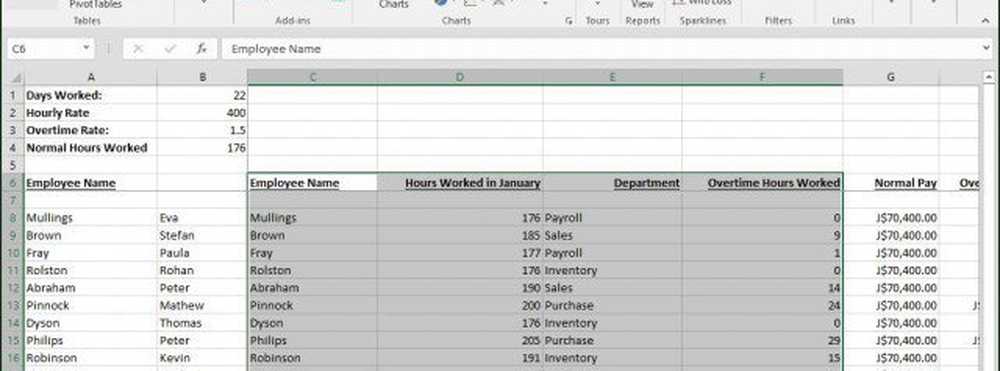
Du kommer märka att ett nytt ark visas med förslag om vad du kan göra. I det här scenariot vill jag veta hur många timmar arbetade med anställda i Försäljningen. För att göra det använder jag helt enkelt avdelningen för att filtrera ner listan och lägga till de andra tabellerna till raderna som anställningsnamnet och ett antal arbetade timmar.
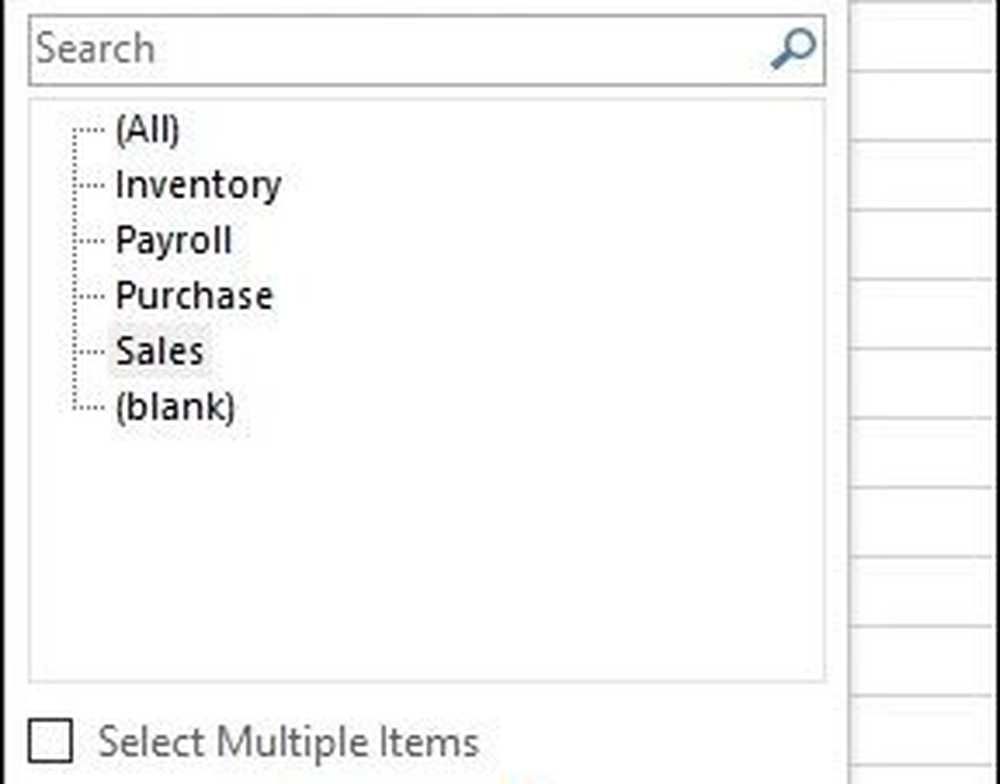
Klicka på Avdelningsfiltret och klicka på Försäljning och sedan OK.
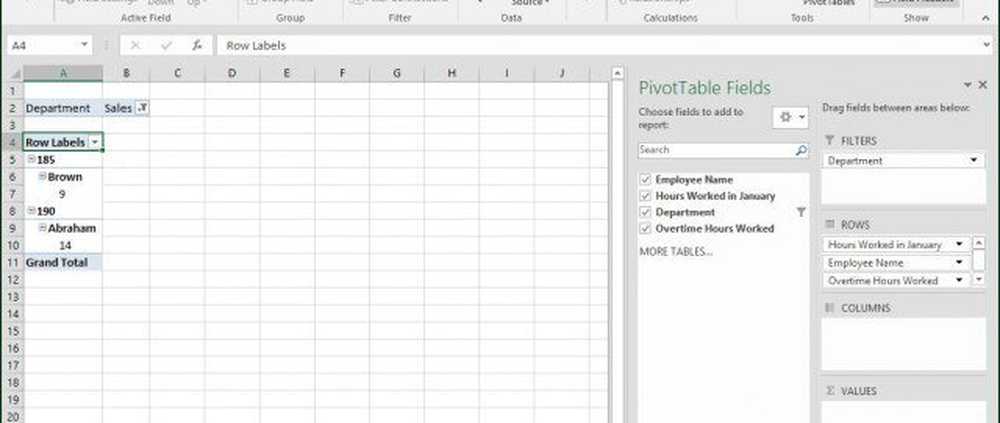
Omedelbart kan jag se vem som arbetade mest. Jag lade till ett extra fält för övertid för att ytterligare analysera informationen som lämnats.
Du borde nu ha en bra uppfattning om hur kraftfulla pivottabeller är och hur de kan spara tid genom att siktra igenom data för att hitta den exakta informationen du behöver med liten ansträngning. För en liten mängd data kan detta vara överkill, men för större mer komplexa dataset gör det ditt jobb mycket enklare.